Hi All,
On one of our newly set up EOS instance of JUNO experiment, we have repeatedly hit the error “Unable to store file - file has been cleaned because of a client disconnect” for hundreds of times. From the error messages, we can see that this error happened on file close. When we hit this error, the certain file is removed from the system.
This is one episode of this errors:
201208 01:24:12 time=1607361852.712424 func=CallManager level=ERROR logid=static… unit=fst@junoeos01.ihep.ac.cn:1095 tid=00007fcf81afc700 source=XrdFstOfs:1084 tident= sec=(null) uid=99 gid=99 name=- geo="" msg=“MGM query failed” opaque="/?&mgm.access=create&mgm.ruid=12328&mgm.rgid=1004&mgm.uid=99&mgm.gid=99&mgm.path=/eos/juno/user/jiangw/Production/J20v2r0-pre1/TestEOS/AmC/elecsim/root/elecsim-200.root&mgm.manager:1094=junoeos01.ihep.ac.cn&mgm.fid=0014f0d5&mgm.cid=149830&mgm.sec=unix|jiangw|hxmt079.ihep.ac.cn||juno|||&mgm.lid=1048850&mgm.bookingsize=1024&mgm.fsid=1&mgm.url0=root://junoeos01.ihep.ac.cn:1095//&mgm.fsid0=1&mgm.url1=root://junoeos04.ihep.ac.cn:1095//&mgm.fsid1=4&cap.valid=1607357213&mgm.pcmd=commit&mgm.size=4373399630&mgm.checksum=6af67882&mgm.mtime=1607361852&mgm.mtime_ns=711088000&mgm.modified=1&mgm.add.fsid=1&mgm.commit.size=1&mgm.commit.checksum=1&mgm.logid=d73797b4-389d-11eb-9c29-0c42a15d0b00"
201208 01:24:27 time=1607361867.924783 func=Close level=ERROR logid=d73797b4-389d-11eb-9c29-0c42a15d0b00 unit=fst@junoeos01.ihep.ac.cn:1095 tid=00007fcf81afc700 source=ReplicaParLayout:500 tident=jiangw.46748:78@hxmt079 sec=unix uid=0 gid=0 name=jiangw geo="" error=failed to close replica root://junoeos04.ihep.ac.cn:1095///eos/juno/user/jiangw/Production/J20v2r0-pre1/TestEOS/AmC/elecsim/root/elecsim-200.root?&cap.msg=Z/kidSdAyI/juId7KxH2ZUMODZmbFjsNfcvCTgIQyotktKxo+wfYdOxqnjcpgltS1HNrSBMT6rZ/tSKimB1MPQYoiK4bqzQ71XZZCxUCvktiTVGZO/LajkGIhe2vD87+Xm8xJCBQhrj6QSbAwg8yznYm0bvo2aWqCoHeKGhTxHGlQuX0cTOymQwN8p6sFOK3V1ZeNLvIoxVZkCXqGwwjstxOQw+SgpfdiJO+wNqTTRAsioJfI+slXE7uz+sU1wlIy7lwrG+5U7oofnGBfJ/RYSLmmoG/jGObap/iWo9WTgy2g0imi3WhfjtRU6oPPFFWR++7YZRzc8nnDgxBLUKPigHX1TYsZ2/bQTNQVtHKbA8LUGqrnJZgRVsljd6XfFyl3zbE0kLmsGcaTdKyXQUCPAIFGbw+SFD7xjCIUMoVHX2ZMc1+mcgQFa2Cvd60Q3g82og9Aeips7zfoa2gySgHpE5ntL8LN8RiN6xGlgjr2jgnZ4bOdglwv0HesPemywV7yLtILHbgwHUnQ8WlGNYVJuFI4dap94QWZO16ZmbQRNMXUsFAQGYA56K0sbSJiZG2/DNcw6koE+adzKZAc6s/9eLIH+t/u7hcZGDGYOZceLBOGMwKSCPRcQ==&cap.sym=iV1RwnSEr1+FpZdsw5F5WM8r538=&mgm.id=0014f0d5&mgm.logid=d73797b4-389d-11eb-9c29-0c42a15d0b00&mgm.replicahead=0&mgm.replicaindex=1&mgm.path=/eos/juno/user/jiangw/Production/J20v2r0-pre1/TestEOS/AmC/elecsim/root/elecsim-200.root
201208 01:24:27 217972 FstOfs_ReplicaParClose: jiangw.46748:78@hxmt079 Unable to close failed ; remote I/O error
201208 01:24:28 217972 FstOfs__close: jiangw.46748:78@hxmt079 Unable to store file - file has been cleaned because of a client disconnect /eos/juno/user/jiangw/Production/J20v2r0-pre1/TestEOS/AmC/elecsim/root/elecsim-200.root; input/output error
eos fileinfo /eos/juno/user/jiangw/Production/J20v2r0-pre1/TestEOS/AmC/elecsim/root/elecsim-200.root
error: cannot stat ‘/eos/juno/user/jiangw/Production/J20v2r0-pre1/TestEOS/AmC/elecsim/root/elecsim-200.root’
(errc=2) (No such file or directory)
Here is the configuration:
Client: xrootd 4.10 ( user opens files with root:// directly , without any fuse )
ROOT: /cvmfs/juno.ihep.ac.cn/centos7_amd64_gcc830/Pre-Release/J20v2r0-Pre0/ExternalLibs/ROOT/6.20.02/bin/root
Server: 4.7.7
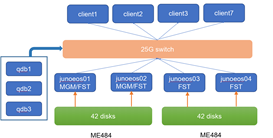
We started 3 FST deamon for each FST server, and the first 3 FST server were shared with QDB servers, the first FST is also MGM.
Any suggestion?


