We have recently upgraded our EOScta eos cluster from version 4.8.75 to version 5.1.8. On version 5.1.8 we are running xrootd 5.5.1.
Since the upgrade, we have seen the MGM hang in a very strange way. The first strange part is that it happens around the same time every 2 days. I have looked at the rest of the system and there seems to be nothing notable happening around this time. When the hanging first starts, a few eosxd clients complain that they cannot access the mount (not all eosxd clients, just some). At this time, xrdlog.mgm contains this entry about 100 times in the space of a few seconds:
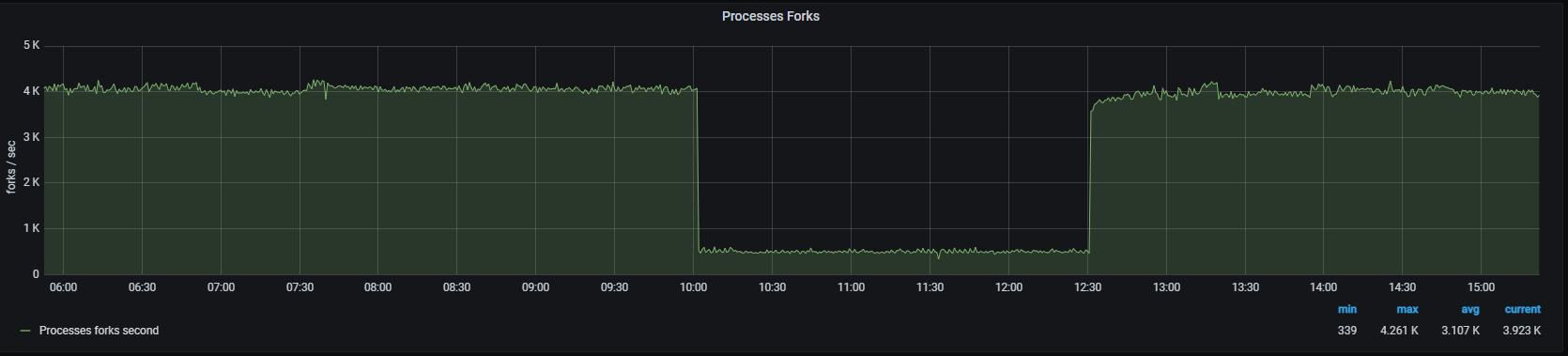
It is as if something is trying to launch the xrootd binary (even though it is already running). From that point on, there is a noticeable decrease in activity on the MGM; as if it is locked up and it not properly servicing requests. Below is a trend for process forks, you can see at 10:00 (when the hang starts), there is much less activity. This lasts around 2.5 hours until 12:30, which is when our k8s liveness check detects that MGM is unhealthy, restarts it and that clears the hang.
The liveness check is running eos ns to detect if the MGM is down. When the MGM is restarted by the k8s liveness check, that is when we lose the rest of the eoxd mounts.
Right before the MGM is restarted, we see this error line each time:
02:31:02 165368 XrdScheduler: Thread limit has been reached!
As I understand, this is an Xrootd specific error. Some google searching indicates that it is a bug in xrootd version 4 (we are on 5 so it should not matter).
Do you have any insight on what might be causing this? Or what further steps I can take to troubleshoot it?
Hi Denis,
normally this smells like a deadlock in the MGM.
When it is in this state send ‘kill -10’ to the MGM first process and collect the file which is created in /var/eos/md/ … maybe additionally create an eu-stack of the MGM process.
eu-stack -p …
Probably the initial daemon does not fully shutdown so it tries to restart but cannot get the port.
Cheers Andreas.
Thanks very much for that! I suspect it is a deadlock too, having collected the stacks you requested. Here is a link to the logs:
The strange behavior started at 2023-03-10T00:00:00 exactly, and the MGM ran out of threads and restarted at 2023-03-10T02:30:00
I included a couple of stack traces from the day before (2023-03-09) to show what it looks like when it’s running normally.
When it started to hang, I captured the eu-stack and stacktrace (kill -10) regularly to see what was changing. It looks like it got to about 5600 threads before falling over:
[root@crlt-v4 mgmdebug]# grep -c TID stack.*
stack.20230309002317:1602 # normal operation from previous day
stack.20230309013631:1602 # normal operation from previous day
stack.20230310002407:1822 # just after hanging
stack.20230310005518:2712 # etc etc
stack.20230310010140:2894
stack.20230310011150:3179
stack.20230310012201:3511
stack.20230310013214:3820
stack.20230310014228:4122
stack.20230310015245:4450
stack.20230310020303:4759
stack.20230310021322:5059
stack.20230310022343:5393
stack.20230310022912:5544
I also solved the mystery of why only some of the eosxd mounts were alerting and not all when the hang starts. It was a buggy healthcheck script, in that it did not have a timeout value, and it would simply hang until the MGM restart, instead of reporting a failure. This is how I fixed it: