Dear experts, can you help me to understand my mistake with LRU setting.
I use documentation:
My settings:
EOS version:
mgm:
{
dvl-eos-m01:~ # eos --version
EOS 4.8.22 (2020)
}
FST:
{
dvl-eos-m01:~ # eos --version
EOS 4.8.22 (2020)
-bash-4.2$ eos --version
EOS 4.3.11 (CERN)
}
Space:
{
dvl-eos-m01:~ # eos space status default
# ------------------------------------------------------------------------------------
# Space Variables
# …
autorepair := on
balancer := on
balancer.node.ntx := 2
balancer.node.rate := 25
balancer.threshold := 20
converter := on
converter.ntx := 10
drainer.node.nfs := 5
drainer.node.ntx := 2
drainer.node.rate := 25
drainperiod := 86400
filearchivedgc := off
geo.access.policy.write.exact := on
geobalancer := on
geobalancer.ntx := 10
geobalancer.threshold := 5
graceperiod := 86400
groupbalancer := on
groupbalancer.ntx := 10
groupbalancer.threshold := 90
groupmod := 50
groupsize := 50
lru := on
lru.interval := 10
quota := off
scaninterval := 604800
scanrate := 100
stat.wfe.active := 0
tracker := off
wfe := on
wfe.interval := 10
wfe.ntx := 1
dvl-eos-m01:~ #
}
Catalog attribute setting:
{ -bash-4.2$ eos attr ls /eos/jinrdvl/tests/zar/pnpicache2 sys.conversion.*="00100002|gathered:RU::JINR::LITDVL" sys.eos.btime="1596273569.773392128" sys.forced.checksum="adler" sys.forced.group="1" sys.lru.convert.match="*:1h" sys.workflow.closew.default="mail:azaroche@cern.ch: a file has been written!" -bash-4.2$
}
I expect all files to copy to this catalog by GEOTAG, but after 1 hour files should change layout to:
“00100002|gathered:RU::JINR::LITDVL" = “plain|gathered:RU::JINR::LITDVL”
I see the first step: all files are saved to nearest FST by geotag:
{ -bash-4.2$ eos fileinfo /eos/jinrdvl/tests/zar/pnpicache2/imm10 File: '/eos/jinrdvl/tests/zar/pnpicache2/imm10' Flags: 0644 Size: 104857600 Modify: Tue Oct 6 21:12:10 2020 Timestamp: 1602007930.531035000 Change: Tue Oct 6 21:12:10 2020 Timestamp: 1602007930.254879876 Birth: Tue Oct 6 21:12:10 2020 Timestamp: 1602007930.254879876 CUid: 13009 CGid: 501 Fxid: 0000005d Fid: 93 Pid: 30 Pxid: 0000001e XStype: adler XS: 5d c0 00 01 ETAGs: "24964497408:5dc00001" Layout: plain Stripes: 1 Blocksize: 4k LayoutId: 00100002 Redundancy: d1::t0 #Rep: 1 ???????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????? ?no.? fs-id? host? schedgroup? path??? boot? configstatus? drain? active? geotag? ???????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????? 0 83 v006.pnpi.nw.ru default.1 /ceph_dev02 booted rw nodrain online RU::PNPI
}
But files do not change layout afterwards. And I do not see any messages about converting or LRU logs in debug mode.
Do you have any ideas? Where is my mistake?
Can you double check your “sys.lru.convert.match” attribute?
Also can you grep in the MGM logs for any errors in the LRU part. For example: grep "LRU" /var/log/eos/mgm/xrdlog.mgm
Did you really mean to use ‘10’ for the LRU interval? This would mean you are starting an LRU scan every 10 seconds. Unless you have a very small EOS instance I doubt the LRU could scan everything in 10 seconds. It may be that it won’t start a new one if one is currently running, but I don’t know that for sure.
If you are trying to get it to run frequently for debugging purposes, I would probably set the interval much higher (at least an hour? 3600) and just turn it off and back on to start a new scan.
Also, I’m not sure if the markup here messed things up, but your sys.lru.convert.match
should probably look like this:
sys.lru.convert.match="*:1h"
And I do not see any messages about converting or LRU logs in debug mode.
i see info log about my access only. As example:
{
/var/log/eos/mgm/Clients.log:201007 17:03:06 INFO [00000/00000] root ::open op=read path=/proc/user/ info=eos.rgid=0&eos.ruid=0&mgm.attr.key=sys.lru.convert.match&mgm.attr.value=base64:Kjo+MWg=&mgm.cmd=attr&mgm.enc=b64&mgm.path=/eos/jinrdvl/tests/zar/pnpicache2&mgm.subcmd=set
/var/log/eos/mgm/Clients.log:201007 17:03:06 DEBUG [00099/00099] - ::open json-callback= opaque=eos.rgid=0&eos.ruid=0&mgm.attr.key=sys.lru.convert.match&mgm.attr.value=base64:Kjo+MWg=&mgm.cmd=attr&mgm.enc=b64&mgm.path=/eos/jinrdvl/tests/zar/pnpicache2&mgm.subcmd=set
}
Thanks.
It is error of edit error. My real setting:
{ sys.lru.convert.match="*:1h"
}
And I changed lru.interval to 360, and change, and restarted LRU:
{ dvl-eos-m01:~ # eos space config default space.lru=off dvl-eos-m01:~ # eos space config default space.lru=on
}
I do not see effect after restart. But, may be we can wait 1 hour for check "sys.lru.convert.match="*:1h" "
O! Sorry, I see my mistake in previous message. I changed lru.interval to 3600,
{
dvl-eos-m01:~ # eos space status default | grep lru
lru := on
lru.interval := 3600
dvl-eos-m01:~ #
}
I will repeat in correct formatting: -bash-4.2$ eos attr ls /eos/jinrdvl/tests/zar/pnpicache2 sys.conversion.*="00100002|gathered:RU::JINR::LITDVL" sys.eos.btime="1596273569.773392128" sys.forced.checksum="adler" sys.forced.group="1" sys.lru.convert.match="*:1h" sys.workflow.closew.default="mail:azaroche@cern.ch: a file has been written!"
Can you restart your MGM and then grep again for LRU in the logs and post the output? I would expect to see at least a message like start LRU scan somewhere in the logs.
Are you using the namespace in memory or in QuarkDB implementation?
After 1 hour I see in the logfile:
{
201008 18:45:52 time=1602171952.086487 func=ConvertMatch level=INFO logid=static… unit=mgm@dvl-eos-m01.jinr.ru:1094 tid=00007f2862ff5700 source=LRU:671 tident= sec=(null) uid=99 gid=99 name=- geo="" time-tag=>1h size-tag=1k <0 >1 limit=1000
}
I probe only:
{ sys.lru.convert.match="*:>1h"
}
But without result too((
Files are not converted…
Maybe I found the error. I see, by log, that LRU is checking script. But I do not see result of converting. I started convert by hand, and see the next error:
{ EOS Console [root://dvl-eos.jinr.ru] |/> file convert /eos/jinrdvl/tests/zar/pnpicache3/imm0 gathered:RU::PNPI error: cannot get default space settings from parent directory attributes (errc=22) (Invalid argument) EOS Console [root://dvl-eos.jinr.ru] |/> attr ls /eos/jinrdvl/tests/zar/pnpicache3 sys.eos.btime="1596273569.773392128" sys.forced.checksum="adler" EOS Console [root://dvl-eos.jinr.ru] |/> attr ls /eos/jinrdvl/tests/zar sys.eos.btime="1596273569.773392128" sys.forced.checksum="adler"
}
Maybe who can comment on this error?
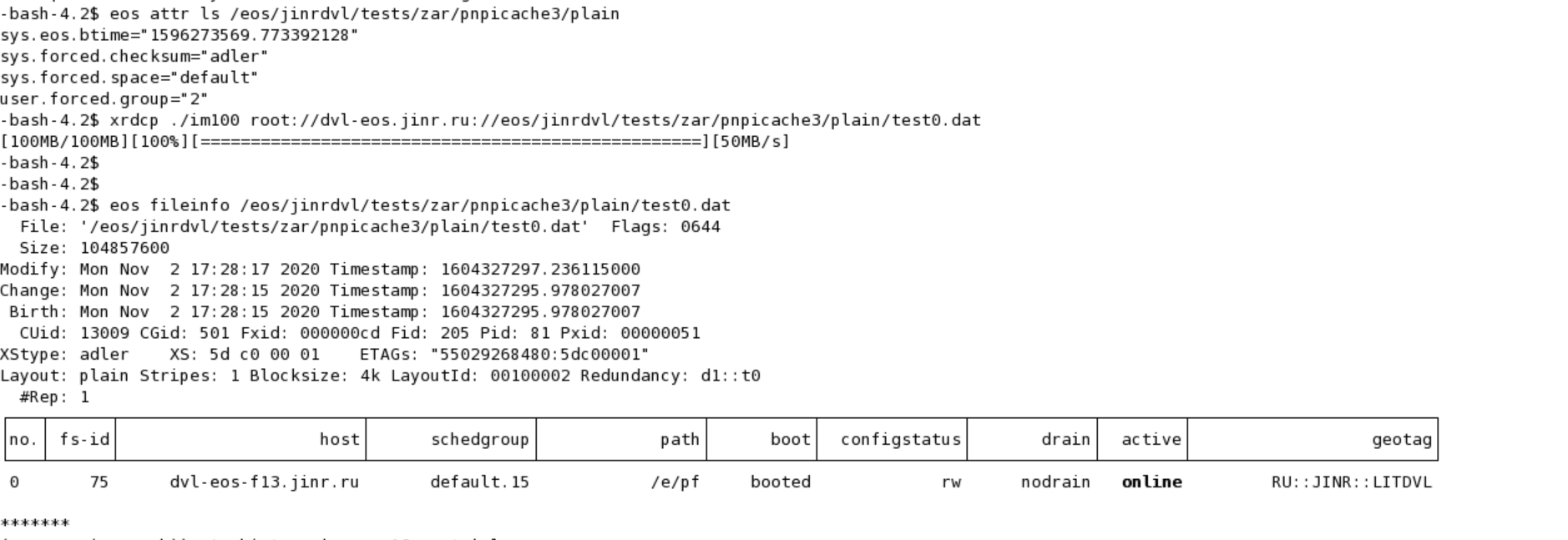
The problem with converting is clear. Need attribute “sys.forced.space” or “user.forced.space”. After fixation:
{ EOS Console [root://dvl-eos.jinr.ru] |/> attr ls /eos/jinrdvl/tests/zar/pnpicache3 sys.eos.btime="1596273569.773392128" sys.forced.checksum="adler" sys.forced.space="default" EOS Console [root://dvl-eos.jinr.ru] |/> file convert --rewrite /eos/jinrdvl/tests/zar/pnpicache3/imm1 'gathered:RU::PNPI' info:: rewriting into space 'default' info: conversion based layout+stripe arguments success: pushed conversion job '0000000000000066:default#00650002' to QuarkDB EOS Console [root://dvl-eos.jinr.ru] |/>
}
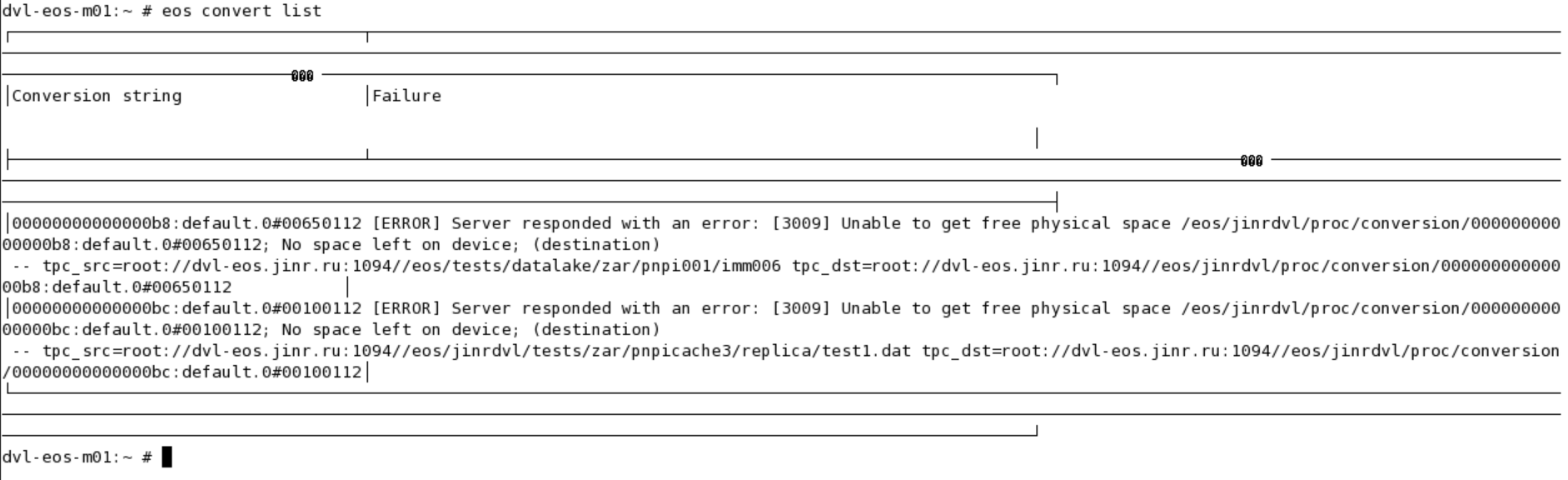
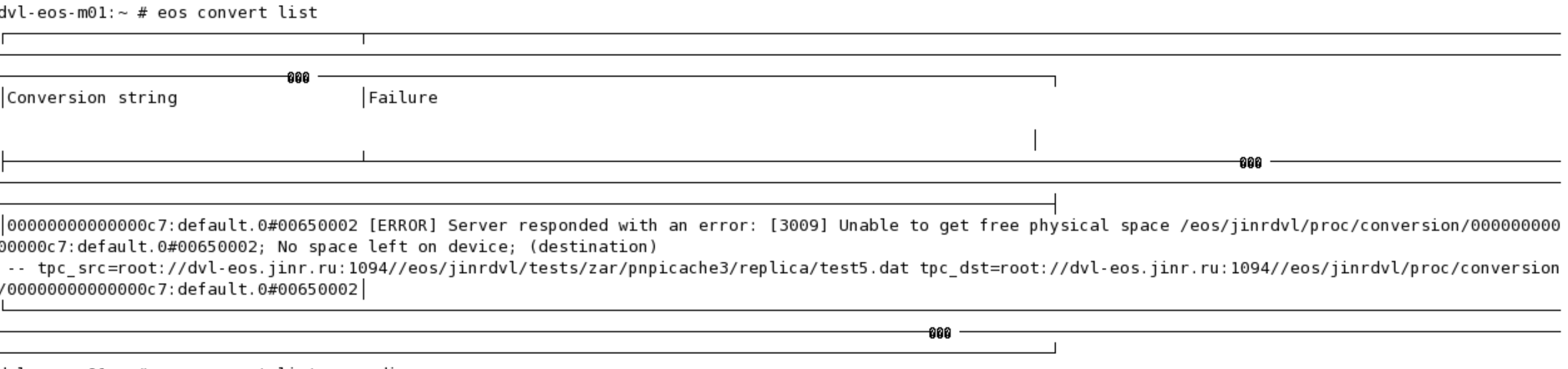
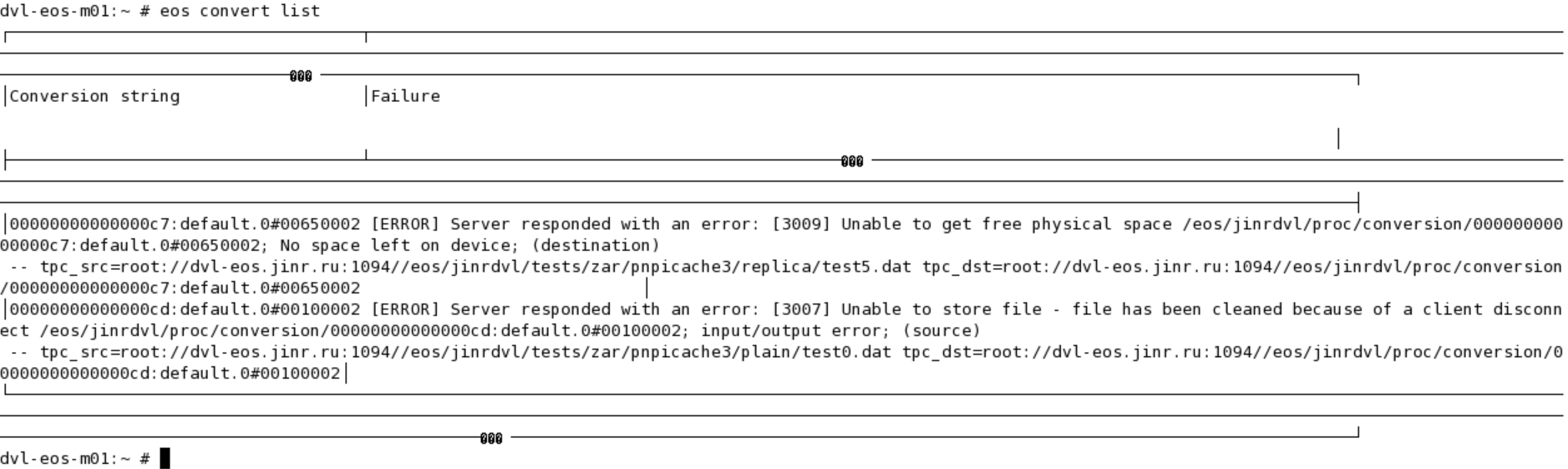
But I see next problem:
{ dvl-eos-m01:~ # eos convert list ............................................................ 0000000000000065:default.0#00650002 [ERROR] Server responded with an error: [3009] Unable to get free physical space /eos/jinrdvl/proc/conversion 0000000000000065:default.0#00650002; No space left on device; (destination) -- tpc_src=root://dvl-eos.jinr.ru:1094//eos/jinrdvl/tests/zar/pnpicache3/imm0 tpc_dst=root://dvl-eos.jinr.ru:1094//eos/jinrdvl/proc/conversion/0000000000000065:default.0#00650002
}
Sorry for the late reply! Let’s try something fresh. Could you please execute the following commands on your instance and post the output? Also please use the following sequence of characters to start the code block and the same to finis it ``` so that it gets properly formatted.
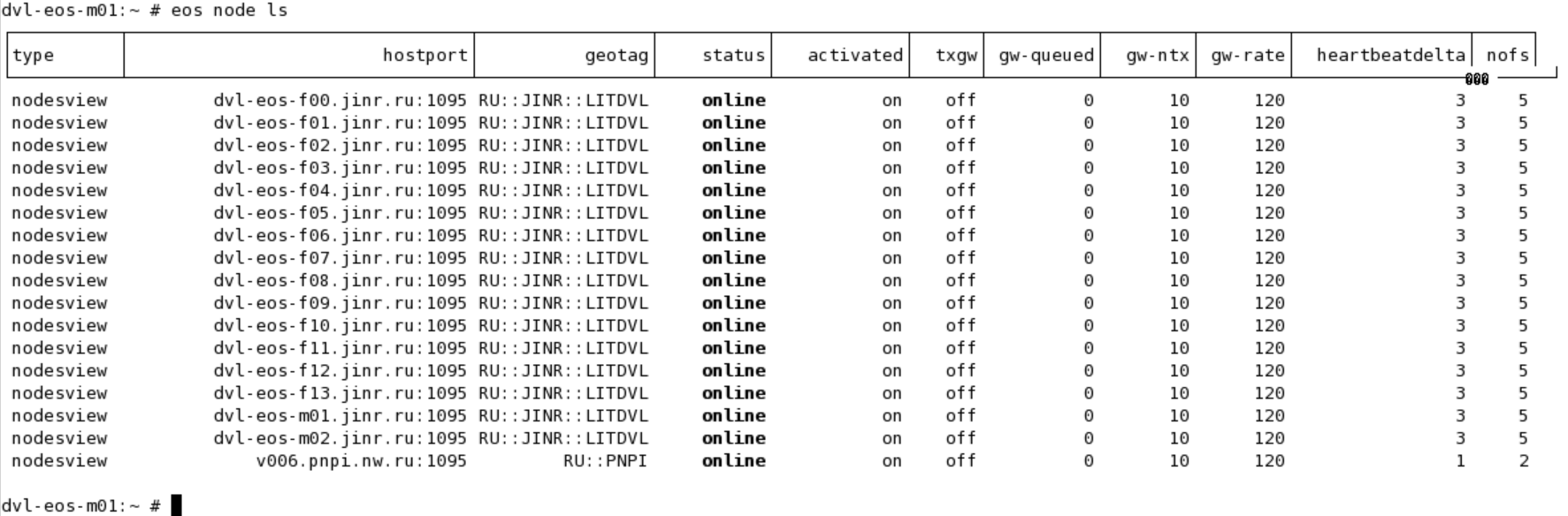
eos node ls
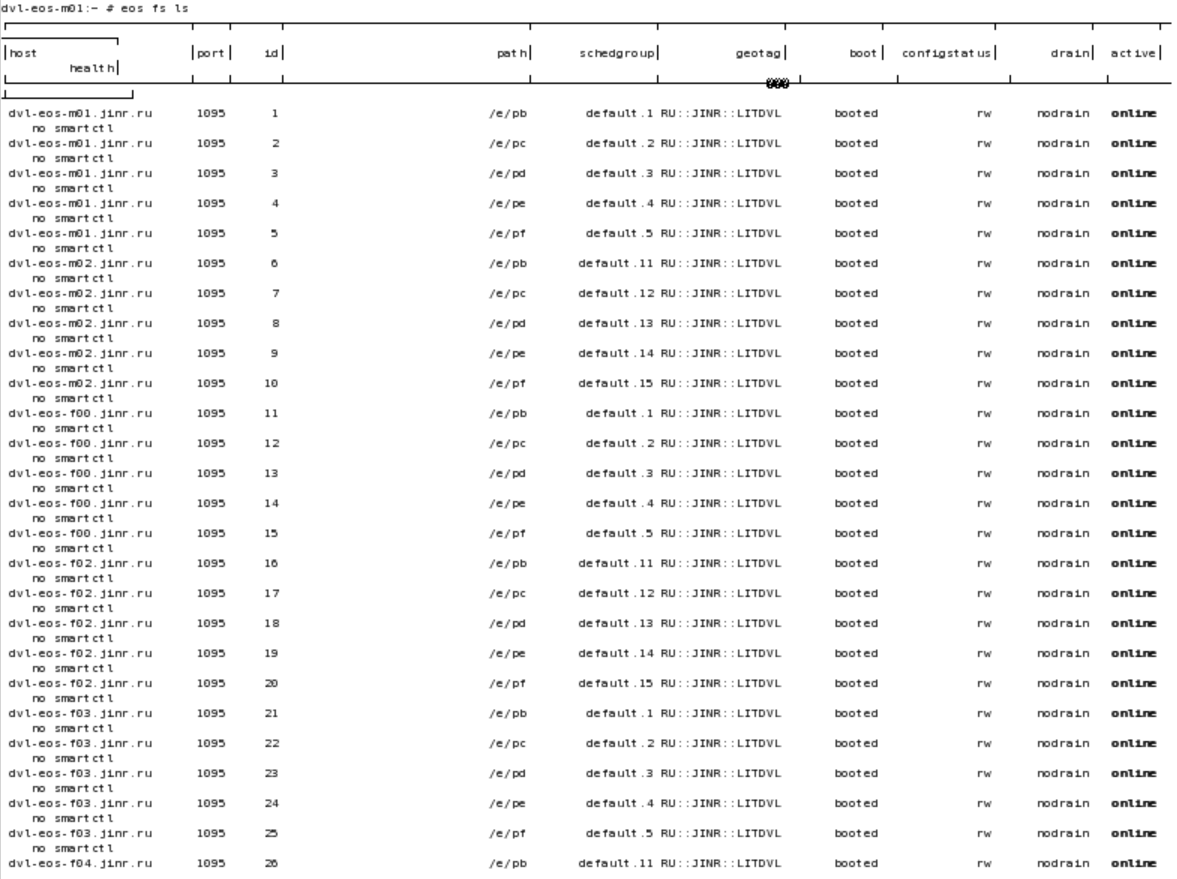
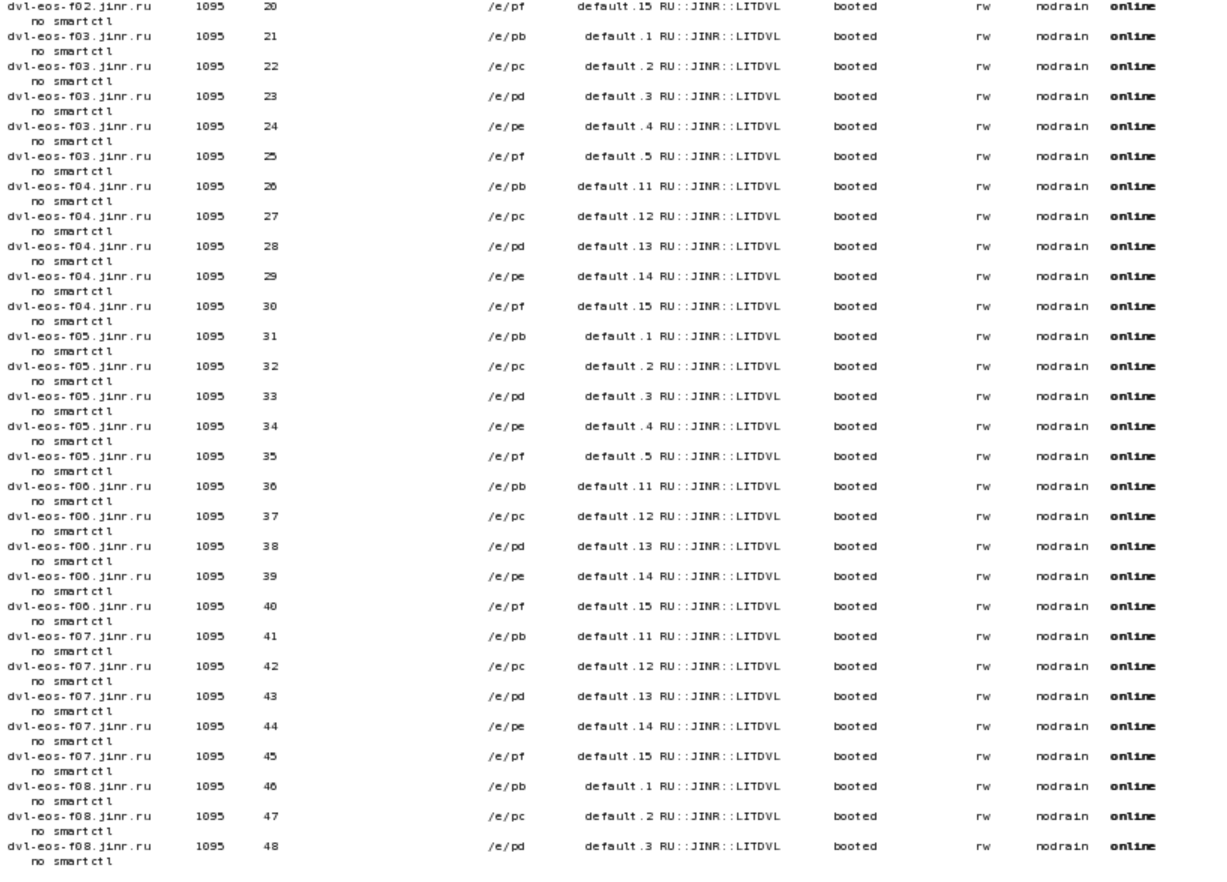
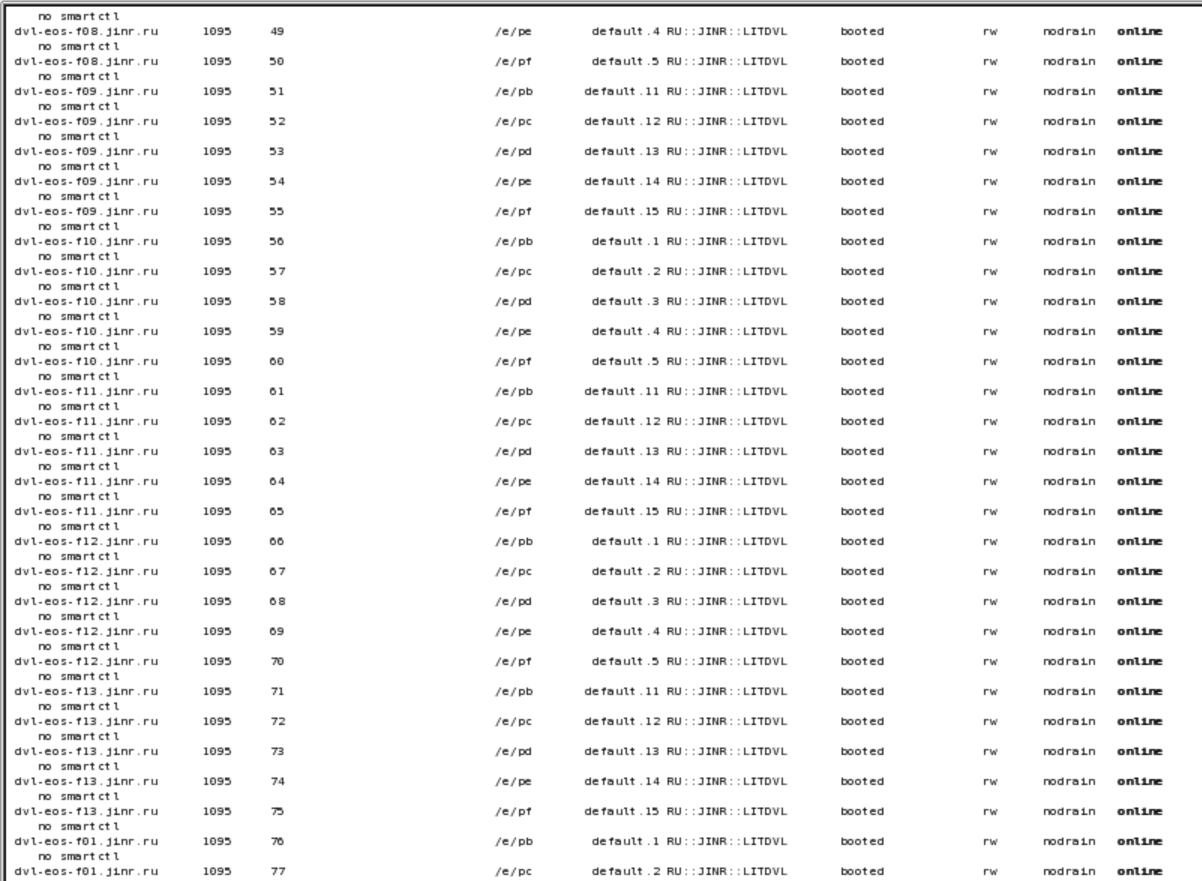
eos fs ls
eos space ls
eos mkdir /eos/jinrdvl/tests/zar/pnpicache3/replica/
eos attr set default=replica /eos/jinrdvl/tests/zar/pnpicache3/replica/
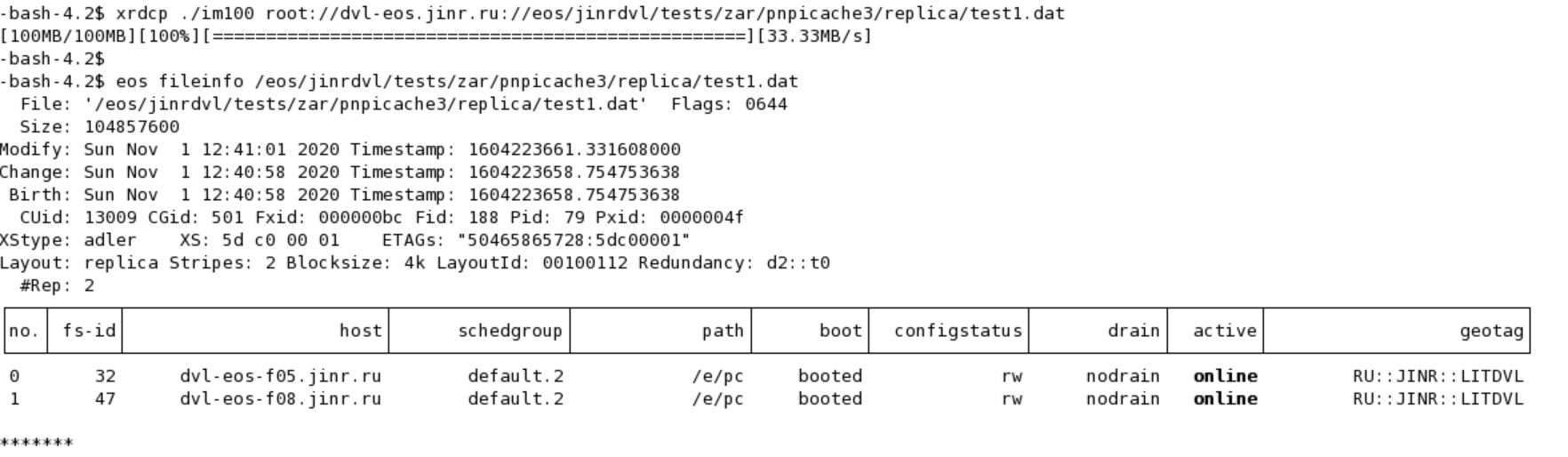
xrdcp -f /etc/passwd root://localhost//eos/jinrdvl/tests/zar/pnpicache3/replica/test1.dat
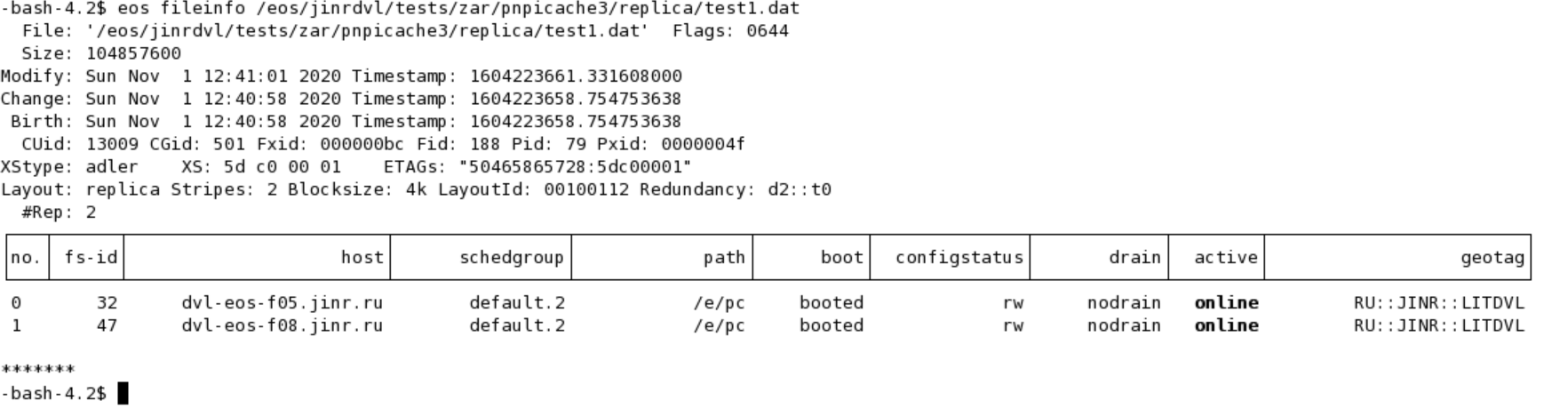
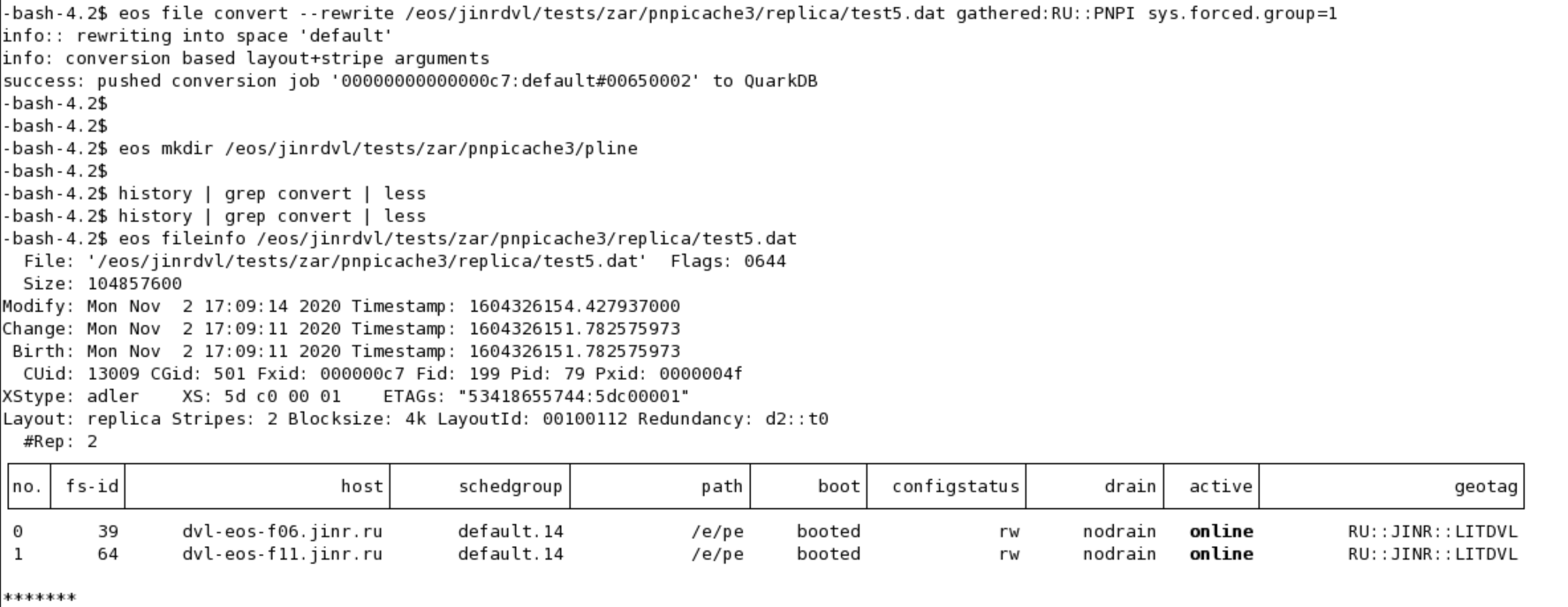
eos fileinfo /eos/jinrdvl/tests/zar/pnpicache3/replica/test1.dat
eos file convert --rewrite /eos/jinrdvl/tests/zar/pnpicache3/replica/test1.dat
Also please let me know if you get any errors in the MGM logs.
Thanks for all the info and especially the logs which helped in finding the problem.
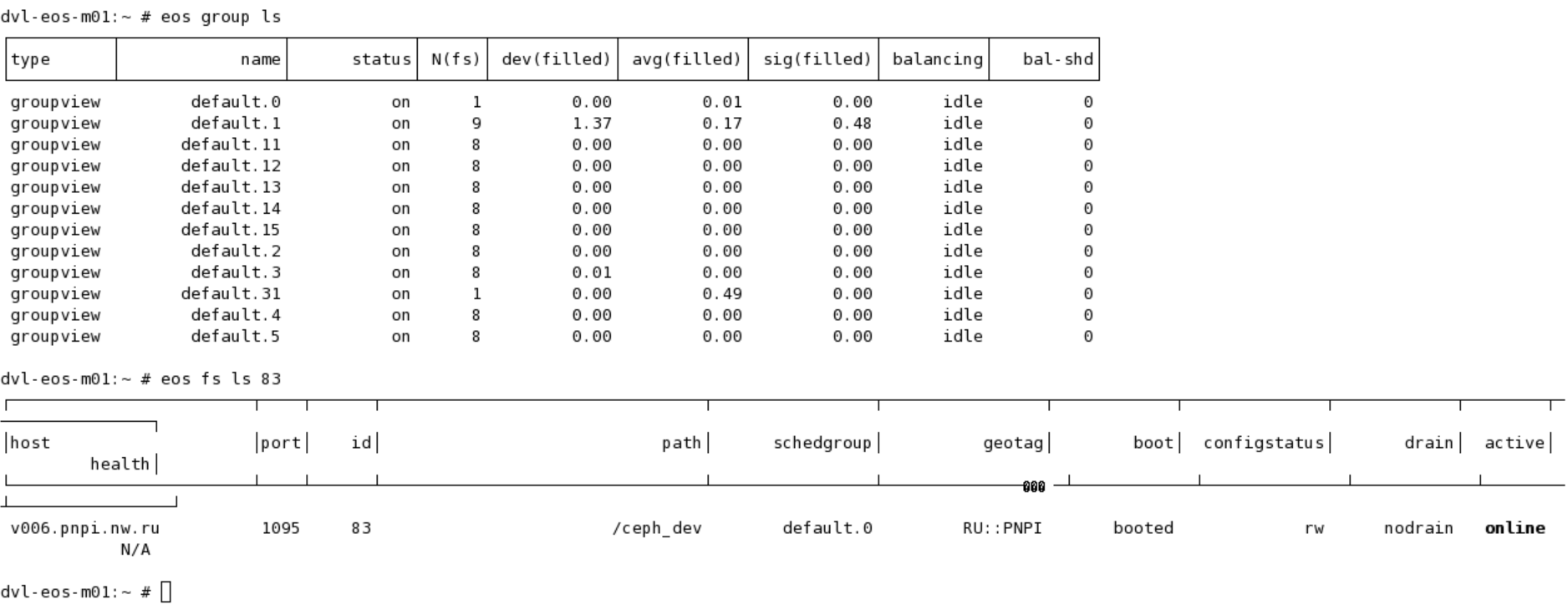
So the issue comes from the fact that you don’t have group 0 in your default space. If no scheduling group is specified explicitly in the convert command the fallback is to use the same space as the original file and group 0 - this means default.0.
But in your particular setup, you don’t have such a group. This most likely comes from the way you configured the instance by explicitly avoiding to create the group 0. The logic in the converter can be improved to select a random group from the current space rather than using this default value - I will fix it in the code for the next release.
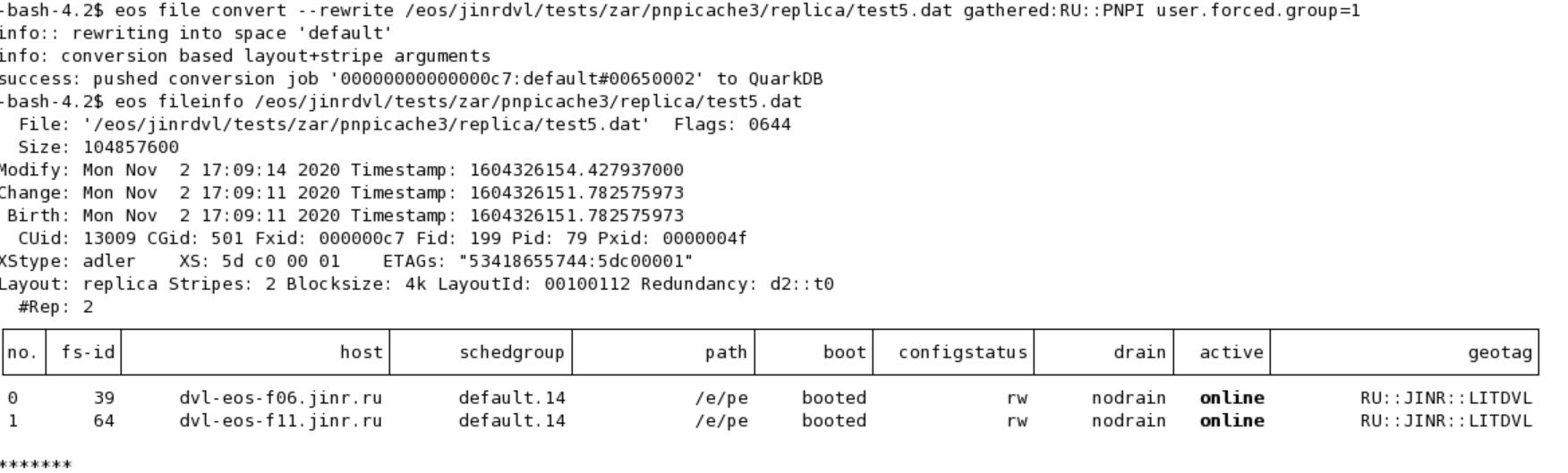
In the meantime, as a workaround please also specify the scheduling group in your converter command and thing should work just fine - for example use default.1. Alternatively, you can also create the default.0 scheduling group by adding a few filesystems to it and then the command will work as it is.
Let me know if this fixes you issue and thanks for this report.
You need to specify the scheduling group to the file convert command as follows:
eos file convert --rewrite <your_file> default.1 gathered:RU::PNPI
Then if you want to add the default.0 group you need to put at least two file systems in it since this is a two replica layout. Give it one more try and let me know.