EOS friends,
The alice::ornl::tmp SE consists of one MGM+FST, currently with 60 x 10TB drives (single disk fsids) attached.
Data is (slowly) being populated, currently this FST serves ~130 TB
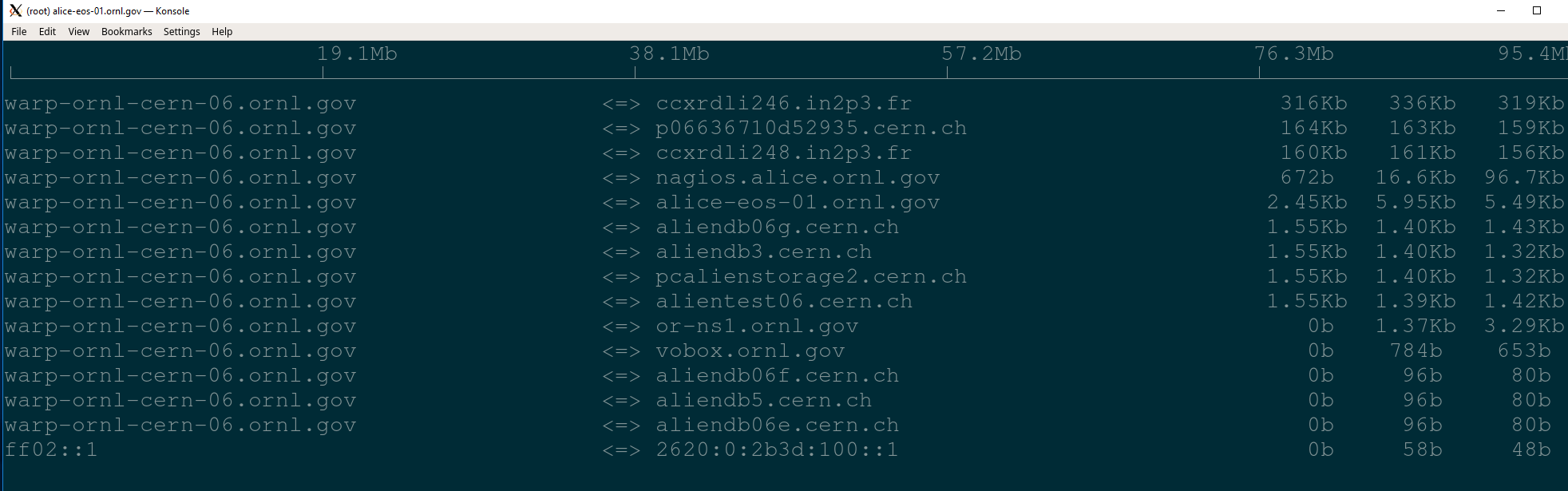
Load on this SE is vastly low, with averages like:
~300 Xrootd tcp established connections
System 15 min LA ~4
<2% IO Wait
Outbound/Inbound TCP is MB/sec magnitudes (or less)
However, despite the near idle eos environment from a performance and resource usage standpoint what is observed is:
Immediately after EOS services complete startup iperf3 results to/from the node plummet from 10Gbit/sec to < half that, with extreme variation, hundreds of tcp retries, the OS interface dropped counter incrementing and the switchport showing discards.
Essentially, starting eos (while under no appreciable demand) completely kills network performance to the node. There is no indications of networking, memory, CPU, or other resource issue - all show an essentially idle environment.
This issue affects the speed at which 3rd party transfer move data, which consistently top out out 20MB/sec, though rsync achieves much faster speeds (when eos is stopped on ornl::tmp and networking returns to normal.)
The ALICE::ORNL::EOS (separate SE) does not see the same issues. The same version of eos (4.3.12-1) is on both SEs.
The same 10G interfaces (Intel X520-2), same kernel versions, same OS, and same in-kernel ixgbe drive are used by all FSTs in both SEs, yet this issue is only present in the alice::ornl::temp SE and FST.
The same recommended 10G sysctl tunings are in place on all nodes (and we’ve adjusted them with no impact on this issue.)
Another issue on this node, which may relate: FST Service Silently Fails
Any suggestions to debug further would be appreciated. We intend to deploy additional nodes in this same configuration, but this is a bit of a showstopper both in migrating data and the stability of the new nodes.
Cheers,
Pete