Currently, our EOS cluster has two JBOD enclosures in one server and is defined as one FST for each enclosure.
Due to the recent CPU performance issue of the FST servers, we would like to separate the FST into two servers.
I’m looking forward to connecting the JBOD enclosure to a new server and automatically attaching it to the EOS pool when I run the EOS configuration and daemon.
However, before actually doing that, I would like to ask you if it works normally even when the node of FST is changed.
I understand that fsid and fsuid are stored on the disk, but if the node changes, wouldn’t the filesystem be recognized normally?
While this is not an operation that we would recommend, as it’s quite risky, you can achieve this by using the following command: eos fs mv --force <fsid> <new_node>:<new_port>
Keep in mind that you should ensure that no two file systems (fsid) from the same machine (node) are in the same group otherwise the prospect of losing a node would most likely prevent you from reading files that have stripes stored on that node!
I would first experiment with this on a test setup before doing it in production.
Is the command not recommended because there is a risk that it could irreversibly corrupt data or cause the system crash? Or are you not recommending it because you haven’t tested it or something?
I’m guessing it’s because of the --force in the command option, but if it’s too risky, I’ll try to find another way.
By the way, I heard from the ALICE computing group that our site generates relatively little traffic from reads and writes, so we assume most of the CPU load comes from disk checks.
Is it true that the CPU load caused by disk scanning is related to the number of disks managed by the FST? Our FSTs manage 84 disks each, and there are 2 FSTs per server, so 168 disks are managed on 1 server. Each server has 16 hyperthreading cores, so if disk scan operations occur per disk, it would explain the high CPU load.
Also, after adding new equipment, the number of threads in individual FSTs seems to have increased. Is it correct that RAIN’s consistency checks are performed in the same way as disk scans?
Considering the above issues, I would like to know if changing the disk scan interval or rate for each FS can reduce CPU resource consumption.
We have nodes that run a single FST daemon which has 120 disks attached without issues. Although it is better to have less disks per FST daemon as it helps with separating the failure domains, this also comes at the cost of more operational maintenance. Furthermore, such a separation would not improve the overall CPU consumption on such a node.
Having said this, it’s true that for RAIN only setups the CPU consumption on the FSTs is higher than replica-only setups, due to the more heavy disk scanning procedure. We noticed this for some time and we planned improvements in this are which are available in the latest releases (but due to the known issues I would recommend running 5.3.14 for this purpose).
The latest release considerably reduces the need for checksum re-computation for RAIN files thus also improving the overall CPU usage. Our disk storage nodes have in general 64 cores and are 80% idle most of the time.
The reason why we don’t recommend the fs mv --force is that in case of a (human) error it can be quite difficult properly restore the state of the system and as I mentioned, the moving around of file systems needs to be done with care to respect the preexisting constraints for the distribution inside groups/nodes. We used this command a couple of times in our instances but it’s something that we do on a regular bases. Nevertheless, this is the appropriate tool to use in this case.
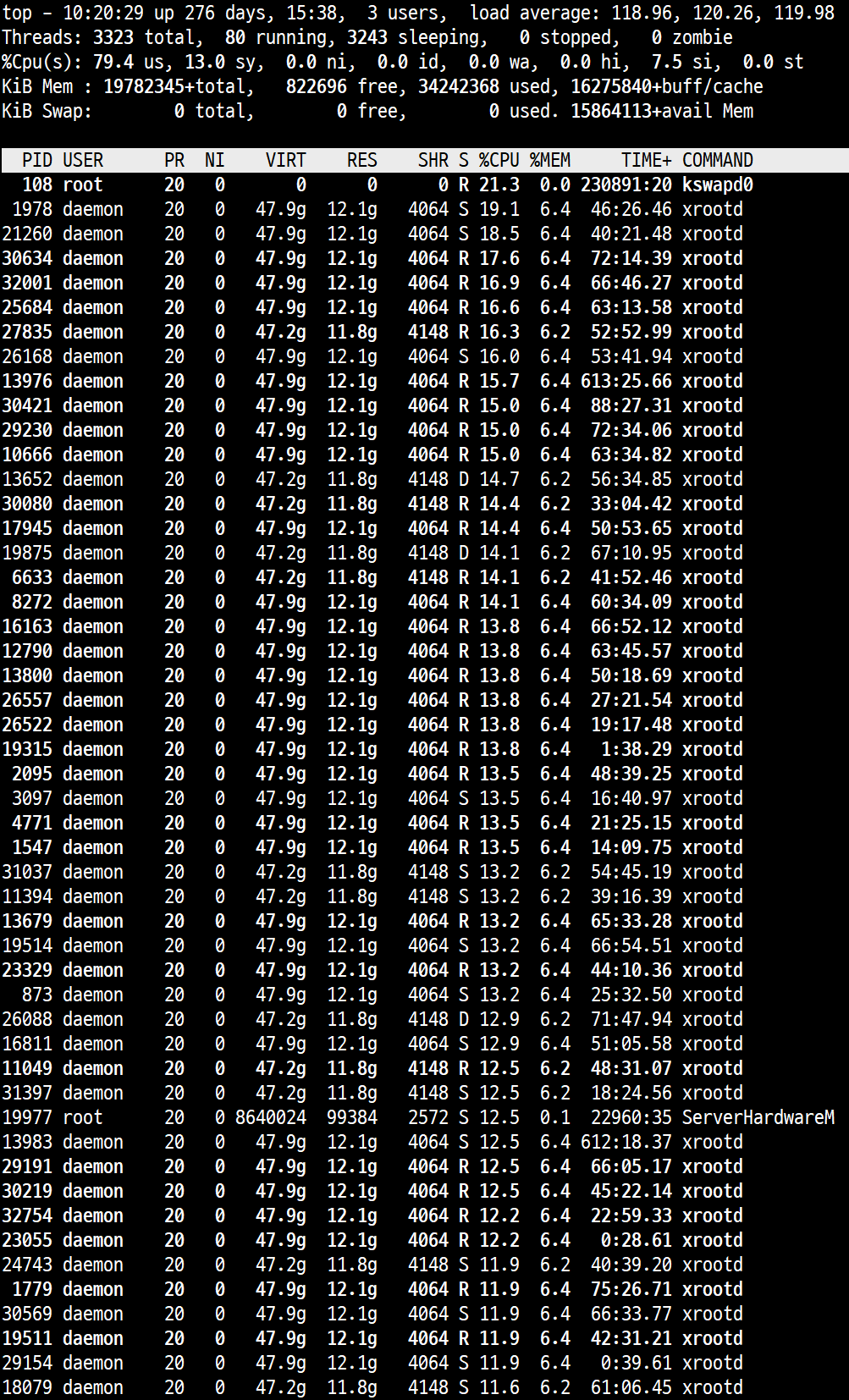
When I look at the top command on a 16-core server, idle is less than 0.1%, and the load average in node ls --sys is around 120~130(8x cores), so I’m thinking that I’m getting a lot of CPU load.
So, we’re hoping that if we can connect the SAS cable from one JBOD enclosure to another server and then fs mv --force to the new FST, the CPU load will be spread across two servers, which will improve the current situation.
Currently, due to frequent test job failures in May, we have been instructed internally to wait until we have sufficient availability to run those tests. We’re downgrading to 5.3.8, which was fine from January through April. We apologize for the delay in testing for version 5.3.14.
Is the CPU saving in RAIN that you mention only supported in 5.3.14 or higher? As I know, it’s a 5.3 feature, so I assume it’s also available in 5.3.8, but I’d appreciate confirmation.
The RAIN scan optimisation is only available from 5.3.13 on. But as you know 5.3.13 is not a good candidate. We already have 5.3.14 running in one of our production instance and the memory usage issue has definitely gone away.
Our diskservers have in general 64 cores and in our case load might be better balanced, but still I would not expect that much usage in our case. For completeness, could you post the output of top -H from one of you diskserves?