Hello,
We have deployed EOS 5.1+ (currently 5.1.29) for ATLAS GRID infrastructure at our site; a single MGM with QuarkDB and 5 FST nodes running on AlmaLinux 8.8.
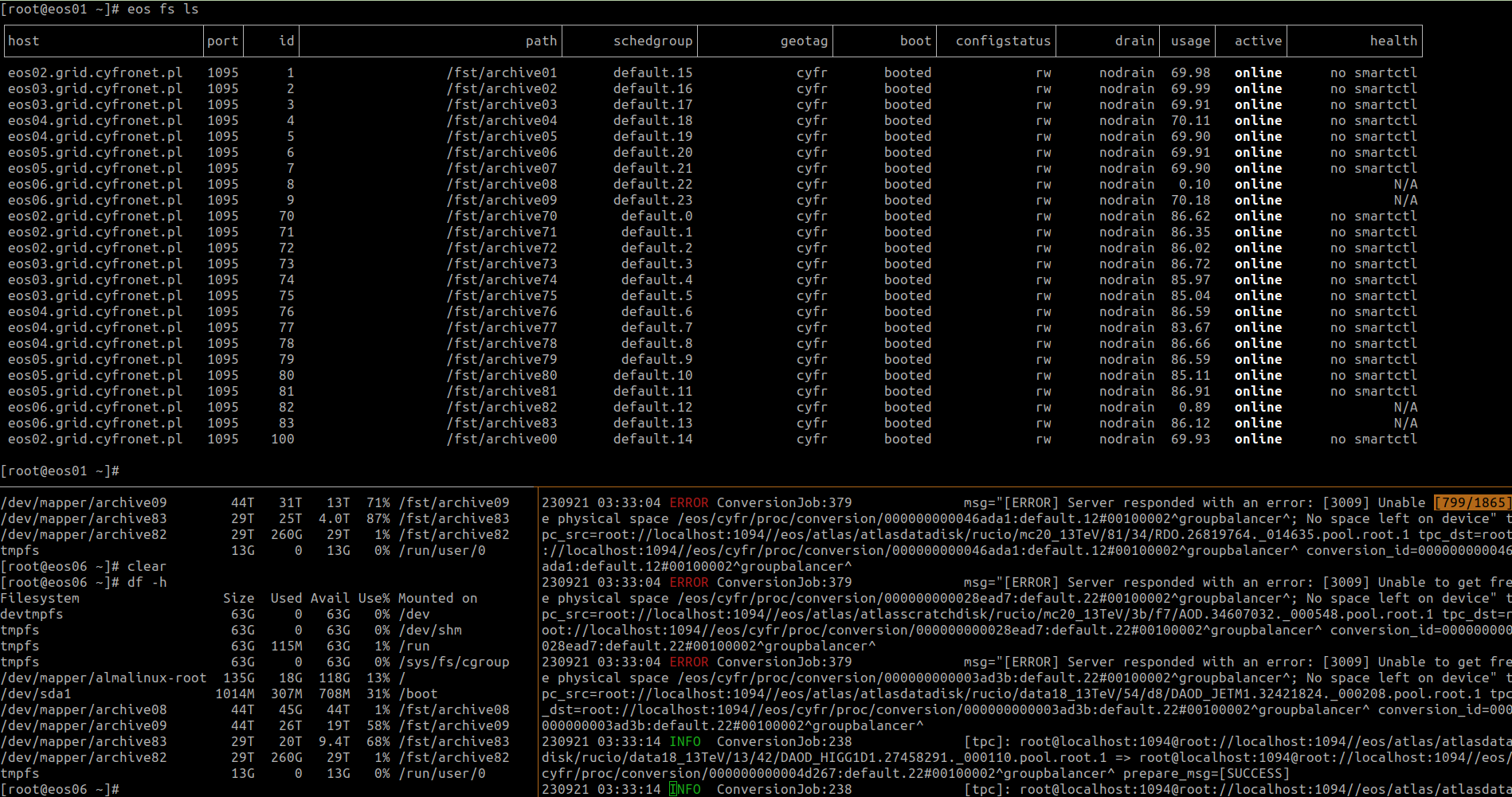
For some reason 2 of our FS’s on single FST have really low space usage, holding way less data than any other FS’s on any of the FST. While investigating situation we have found that GroupConverter logs a lot of errors (example): ERROR ConversionJob:379 msg="[ERROR] Server responded with an error: [3009] Unable to get free physical space /eos/cyfr/proc/conversion/000000000003f3a7:default.12#00100002^groupbalancer^; No space left on device" tpc_src=root://localhost:1094//eos/atlas/atlasdatadisk/rucio/data17_13TeV/ea/22/DAOD_JETM1.32822114._000073.pool.root.1 tpc_dst=root://localhost:1094//eos/cyfr/proc/conversion/000000000003f3a7:default.12#00100002^groupbalancer^ conversion_id=000000000003f3a7:default.12#00100002^groupbalancer^
despite having a lot of free space (all of the FS’s are online and in RW mode - screen):
Each of /fst/archiveXX directory has owner daemon:daemon and the permissions are set to 755 . We can manualy create, modify and delete files (tested up to couple of GigaBytes) on problematic FS’s.
We do not know where to look further in order to solve this problem. It also affects draining process.
Any suggestions and feedback are much appreciated, i will update this question if more details are needed.
Cheers
Please run the following command and then restart the MGM daemon. Once this is done then all of your FSTs should be used by the groupbalancer and also for direct file placement. There is a bug in the scheduling implementation that is triggered when the skipSaturatedAccess & co. are enabled and this prevents some of the disks to be properly used for placement of new files.
sudo eos geosched set skipSaturatedAccess 0
sudo eos geosched set skipSaturatedDrnAccess 0
sudo eos geosched set skipSaturatedBlcAccess 0
Hi,
sadly changing those parameters did not solve our problem, apart of restarting the MGM daemon itself we have also tried rebooting MGM node and one FST containing “bad” FS’s afterwards.
I attach some new logs in case in case they have changed since:
230926 14:33:48 ERROR ConversionJob:379 msg="[ERROR] Server responded with an error: [3009] Unable to get free physical space /eos/cyfr/proc/conversion/00000000004f0ad6:default.12#00100002^groupbalancer^; No space left on device" tpc_src=root://localhost:1094//eos/atlas/atlasdatadisk/rucio/mc23_13p6TeV/ab/d3/HITS.34928691._003890.pool.root.1 tpc_dst=root://localhost:1094//eos/cyfr/proc/conversion/00000000004f0ad6:default.12#00100002^groupbalancer^ conversion_id=00000000004f0ad6:default.12#00100002^groupbalancer^
230926 14:33:48 ERROR ConversionJob:379 msg="[ERROR] Server responded with an error: [3009] Unable to get free physical space /eos/cyfr/proc/conversion/000000000005884e:default.12#00100002^groupbalancer^; No space left on device" tpc_src=root://localhost:1094//eos/atlas/atlasdatadisk/rucio/data16_13TeV/d3/85/DAOD_HIGG1D1.27457343._000174.pool.root.1 tpc_dst=root://localhost:1094//eos/cyfr/proc/conversion/000000000005884e:default.12#00100002^groupbalancer^ conversion_id=000000000005884e:default.12#00100002^groupbalancer^
Can you post the output of the following commands: eos geosched show tree eos geosched show param eos attr ls /eos/cyfr/proc/conversion eos space ls default
eos attr ls /eos/cyfr/proc/conversion
it returns nothing, as no parametes are set for this directory, in case its needed i also post the attrs for the proc directory, which were set for the accounting eos attr ls /eos/cyfr/proc
In addition i checked the owner for files/directories inside proc, not all of them are owned by daemon, but i do not know is fine for EOS workings. os ls -lah /eos/cyfr/proc
Do you plan to use 2 replicas for the layouts or just simple files? If you don’t use any replication then put all the file systems in just one group (default.0). You can do this by using the eos fs mv -f command.
If you do plan to use replication then I would recommend a number of groups equal to the max number of file systems on your machines. Then put one file systems from each machine in a different group from other file systems from the same machine.
Once your groups and file systems are restructured issue eos geosched forcerefresh and send again the output of eos geosched show tree.
Hi,
As each of our FS’s provides like RAID6 capabilites, we are not using any kind of file replication.
We have moved all FS’s to a single group, ran required commands and now the behave more or less as expected - new files are landing on all FS’s, including those problematic ones. Here’s the output of eos geoshed show tree
Although our problems have been fixed, this is a stopgap solution only, the group balancer bug (?) still remains. My understanding of the documentation points to our previous config as a correct way of achieving our goals.
Thanks for providing all of the guidance and presenting working solution,
Cheers
Given that you now have file systems in just one group, you no longer need to run the groupbalancer since there is nothing to balance between groups. At this point you should enable the simple balancer to make sure the data is evenly distributed between the file systems in the same group (in your case the only group default.0).
My suspicion of why the group balancer failed, is that by default the space policy assumes a replica layout with 2 replicas. In the beginning you only had groups with one file system so there was no group that could be selected to place a file with 2 replicas - this is the reason for the initial error.
In the current setup, you only have one group so the groupbalancer can not find another group where to balance the files - and this is probably the reason for the failures that you currently get.
Therefore, please try enabling the normal balancer and do one more eos geosched forcerefresh before that, and let me know if things improve.